

Abstract neural network with glowing data structures illustrating Model Context Protocol for AI mastery.
The landscape of Artificial Intelligence is rapidly evolving, with Large Language Models (LLMs) at its forefront, capable of astonishing feats of language generation and understanding. Yet, for developers building real-world AI applications, a persistent frustration often emerges: the AI's apparent inability to remember, its tendency to provide inaccurate answers, and its struggle with complex, multi-turn interactions. This isn't a flaw in the LLM's intelligence; it's a fundamental challenge rooted in how these models process information – or, more accurately, how they don't inherently retain it.
The core issue lies in context. Without a robust mechanism to provide and manage relevant information, LLMs operate in a stateless manner, effectively forgetting previous interactions with each new query. This leads to the common pain points of 'forgetful' chatbots, inaccurate responses, and the hard ceiling imposed by context window limitations.
This article is your definitive guide to transcending these limitations. We'll embark on a journey from diagnosing the 'context crisis' in AI to mastering foundational context management techniques. Crucially, we will introduce and explore the Model Context Protocol (MCP) – an emerging open-source standard poised to become the universal connector for AI, akin to USB-C for hardware. You'll learn not only why context is paramount but also how to implement structured context and MCP in your own projects with actionable code, transforming your unreliable AI into a coherent, production-ready, and truly intelligent application.
The Context Crisis: Why Your AI Keeps Forgetting
At the heart of many AI application failures is a misunderstanding or mishandling of context. LLMs, despite their impressive capabilities, are not inherently designed for stateful memory. This inherent characteristic, coupled with technical constraints, creates a "context crisis" that developers must actively address.

Understanding the 'Stateless' Nature of LLMs
Imagine trying to have a coherent conversation with someone who has severe short-term memory loss. They might respond intelligently to your current sentence, but they'd have no recollection of what you said moments ago, who they are talking to, or the overall topic of discussion. This is analogous to how most LLMs operate by default. Each API call to an LLM is typically treated as an independent event. The model receives a prompt, processes it, and generates a response, but it doesn't inherently store any information about that interaction for future calls. This is what we mean by LLMs being stateless. To make them appear stateful and context-aware, developers must explicitly manage and re-inject relevant information with each subsequent prompt.
The Context Window Bottleneck: When AI 'Forgets'
To overcome statelessness, we provide LLMs with context – the preceding conversation, relevant documents, or specific instructions – within a single prompt. However, there's a limit to how much information can be included in any given prompt. This limit is known as the context window, measured in tokens. A token is roughly equivalent to a word or a piece of a word.
Different LLMs have vastly different context window sizes. For instance, older models like GPT-3 might have a context window of around 2,049 tokens, while newer, advanced models like Google's Gemini 1.5 can boast up to 1,000,000 tokens. When the total number of tokens in your prompt (including the user's input, previous conversation history, and any retrieved documents) exceeds the model's context window, the model simply cannot process all the information. Older parts of the conversation or document are truncated and effectively "forgotten." This bottleneck is a significant hurdle for tasks involving long documents, extensive dialogue, or complex reasoning that requires synthesizing information from many sources.
Context Window Comparison:
- GPT-3: ~2,049 tokens
- GPT-4: ~8,192 to ~128,000 tokens (depending on version)
- Claude 3: ~200,000 tokens
- Gemini 1.5 Pro: ~1,000,000 tokens
The challenge isn't just about having a large context window; it's about effectively utilizing it. Even with a million tokens, a poorly structured or irrelevant prompt will yield poor results. For more details on how models like Gemini handle extended context, you can refer to Google's Approach to Long Context in LLMs.
Hallucinations and Inaccuracies: The Cost of Missing Context
When an LLM lacks sufficient or accurate context, it doesn't just fail to answer; it can actively generate incorrect information. This phenomenon is often referred to as hallucination. Hallucinations can range from subtle factual errors to completely fabricated statements presented with high confidence.
Several factors contribute to AI inaccuracies:
- Insufficient Context: The model may not have enough information to form a correct answer, leading it to guess or extrapolate incorrectly.
- Conflicting Context: If provided with contradictory information, the model might struggle to reconcile it, leading to nonsensical outputs.
- Flawed Training Data: LLMs are trained on vast datasets. If this data contains biases, errors, or outdated information, the model can internalize and reproduce these inaccuracies.
- Model Architecture: The very pattern-matching nature of LLMs can sometimes lead them to generate plausible-sounding but factually incorrect statements, a phenomenon explored in academic research such as the paper on out-of-context meta-learning.
These inaccuracies can manifest in different ways. We might see a "Confident Generalization," where the model makes a broad statement based on limited examples. A "Logical Leap" occurs when the model draws a conclusion that doesn't logically follow from the provided context. Most concerning is the "Invented Fact," where the model fabricates information entirely. Understanding these failure modes, as discussed in resources like AI Hallucination Examples, is the first step toward mitigation. The underlying issue often traces back to how context is managed, or mishandled, during the inference process.
A Maturity Model for Managing Conversational Context
To combat the "context crisis," developers need a structured approach. Context management isn't a one-size-fits-all solution; it's a spectrum of techniques that can be applied based on the complexity of the AI application. We can frame this as a Maturity Model for Context Management, guiding you from basic implementations to sophisticated, production-ready systems.
Level 1: Basic Context Storage (Variable & History Buffers)
The simplest way to introduce context into an AI application is to store and re-inject the conversation history.
- Conversation History Buffer: In a chatbot, you can maintain a list of previous user messages and AI responses. With each new user query, you append it to this list, then send the entire history (up to the LLM's context window limit) as part of the prompt.
- Variable Storage: For simpler tasks, you might store specific pieces of information (like a user's name, a selected option, or a calculated value) in variables and inject them into prompts as needed.
Pros: Easy to implement, requires minimal overhead.
Cons: Quickly hits context window limits for longer conversations. Lacks sophisticated understanding of context relevance. Can become unwieldy for complex state tracking.
For example, a basic Python implementation might look like this:
class Chatbot:
def __init__(self, llm_client):
self.llm_client = llm_client
self.conversation_history = []
def chat(self, user_message):
# Add user message to history
self.conversation_history.append({"role": "user", "content": user_message})
# Construct the prompt with history
# In a real scenario, you'd need to manage token limits here
prompt_messages = self.conversation_history
# Send to LLM
response = self.llm_client.generate(prompt_messages)
# Add AI response to history
self.conversation_history.append({"role": "assistant", "content": response})
return response
# Example Usage (conceptual)
# llm = LLMClient("your_api_key")
# bot = Chatbot(llm)
# print(bot.chat("Hello, what's my name?"))
# print(bot.chat("What did I ask before?")) # This would fail without context managementLevel 2: Structured Context and State Machines
As applications grow more complex, relying solely on raw conversation history becomes insufficient.
- Structured Context: Instead of just passing raw text, you can structure the context into formats like JSON. This allows you to represent specific entities, relationships, and states more explicitly. For instance, you could have a JSON object detailing the user's profile, current task status, and relevant external data, which is then fed into the LLM. This is a core aspect of context engineering, a concept championed by AI leaders like Andrej Karpathy.
- State Machines: A state machine is a computational model that can be in exactly one of a finite number of states at any given time. For conversational AI, a state machine can manage the flow of the conversation, dictating what the AI should do or say based on the current state and user input. For example, an e-commerce bot might have states like
awaiting_product_selection,awaiting_payment_details,order_confirmed.
Using structured data, like JSON, can significantly improve an AI's ability to understand and act upon context. For instance, when dealing with documents, ensuring they are properly structured, as discussed in Enhancing AI Contextual Understanding with Properly Structured PDF Documents, can lead to more accurate information retrieval.
Level 3: Advanced Context Management (Memory Architectures & Agents)
For highly sophisticated AI applications, such as autonomous agents or complex knowledge management systems, more advanced techniques are employed:
- Hierarchical Memory Systems: These systems mimic human memory by distinguishing between short-term, working memory (akin to the context window) and long-term memory (a persistent knowledge base). Information can be summarized, compressed, and stored in long-term memory, and relevant snippets can be retrieved and loaded into working memory as needed.
- AI Agents: AI agents are designed to perceive their environment, make decisions, and take actions to achieve specific goals. They often incorporate sophisticated context management, including memory systems, tool use, and planning capabilities, to operate effectively over extended periods and complex tasks. Platforms like AutoKitteh provide insights into Developing Stateful AI Agents, showcasing how statefulness is crucial for agentic behavior.
The Model Context Protocol (MCP): The Universal Connector for AI
While the above techniques improve how AI understands context, a significant challenge remains in how AI models interact with the outside world – with tools, APIs, and databases. This is where the Model Context Protocol (MCP) emerges as a game-changer.
What is MCP and Why Does it Matter?
MCP is an open-source protocol designed to standardize the way AI models communicate with external tools and functionalities. Think of it as the USB-C for AI. Just as USB-C provides a universal standard for connecting various devices to computers, MCP aims to provide a universal standard for AI models to access and utilize a vast array of external capabilities.
Before MCP, integrating an LLM with a specific tool often required custom, brittle code for each integration. Developers had to build bespoke "adapters" for every API or service. MCP standardizes this interaction, allowing an LLM to discover, understand, and invoke tools in a consistent manner, regardless of the tool's underlying technology.
This standardization leads to several key benefits:
- Interoperability: AI models can seamlessly work with a wide range of tools and services without custom integration code for each.
- Faster Development: Developers can leverage existing tools and services more rapidly, focusing on the AI logic rather than plumbing.
- Enhanced Capabilities: AI applications can become far more powerful by accessing real-time data, performing complex calculations, or interacting with external systems directly.
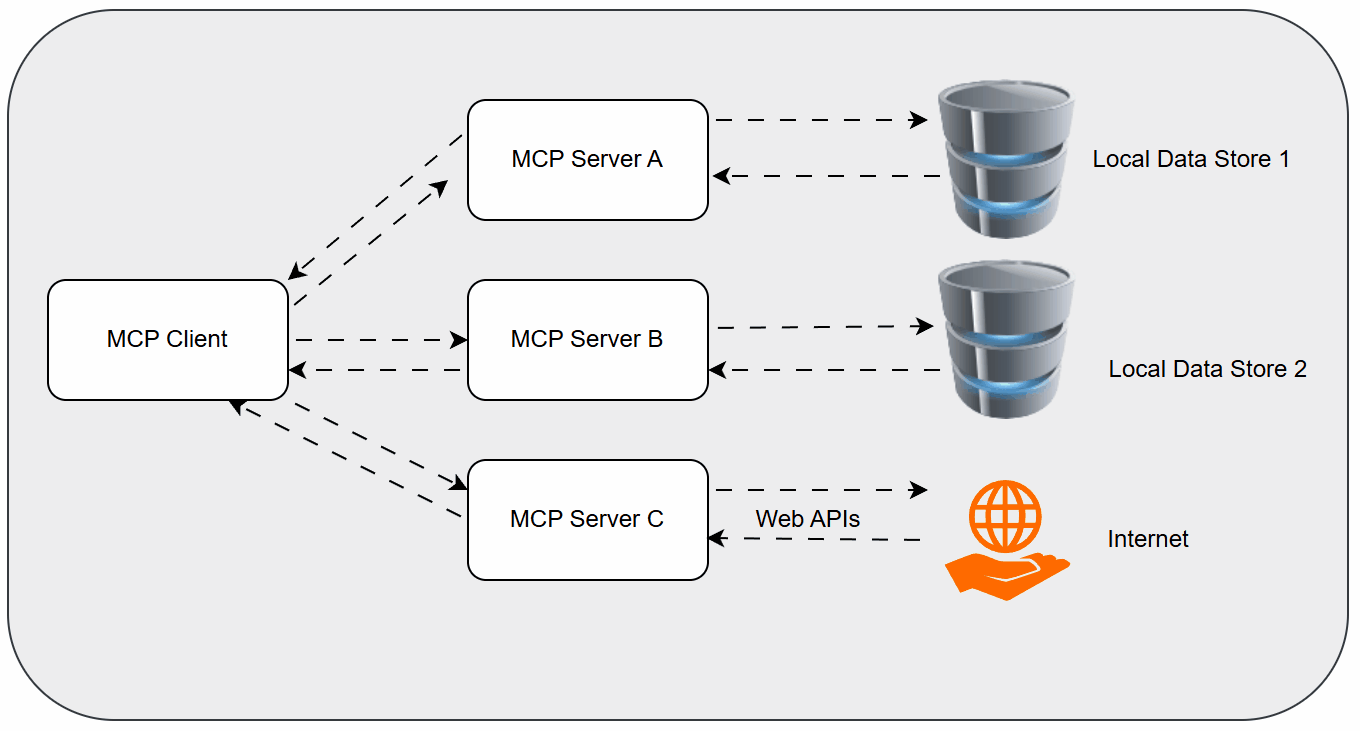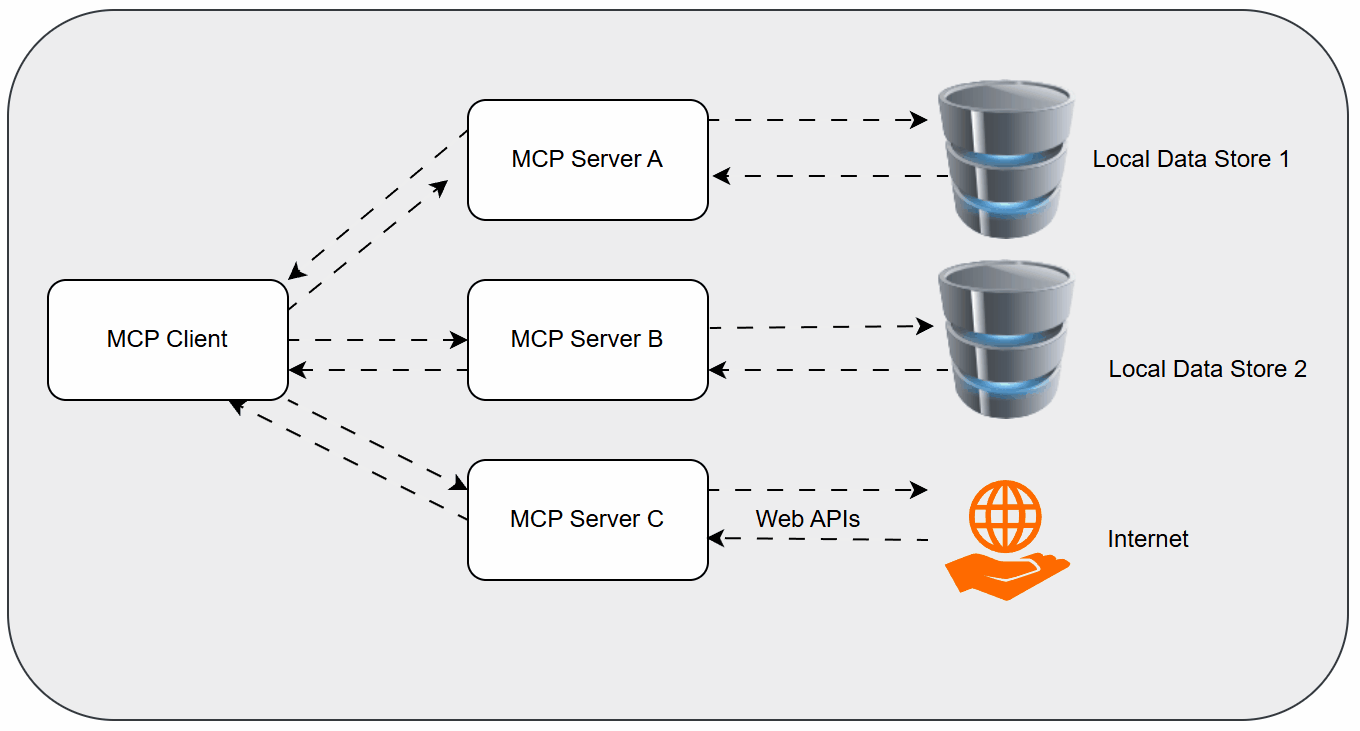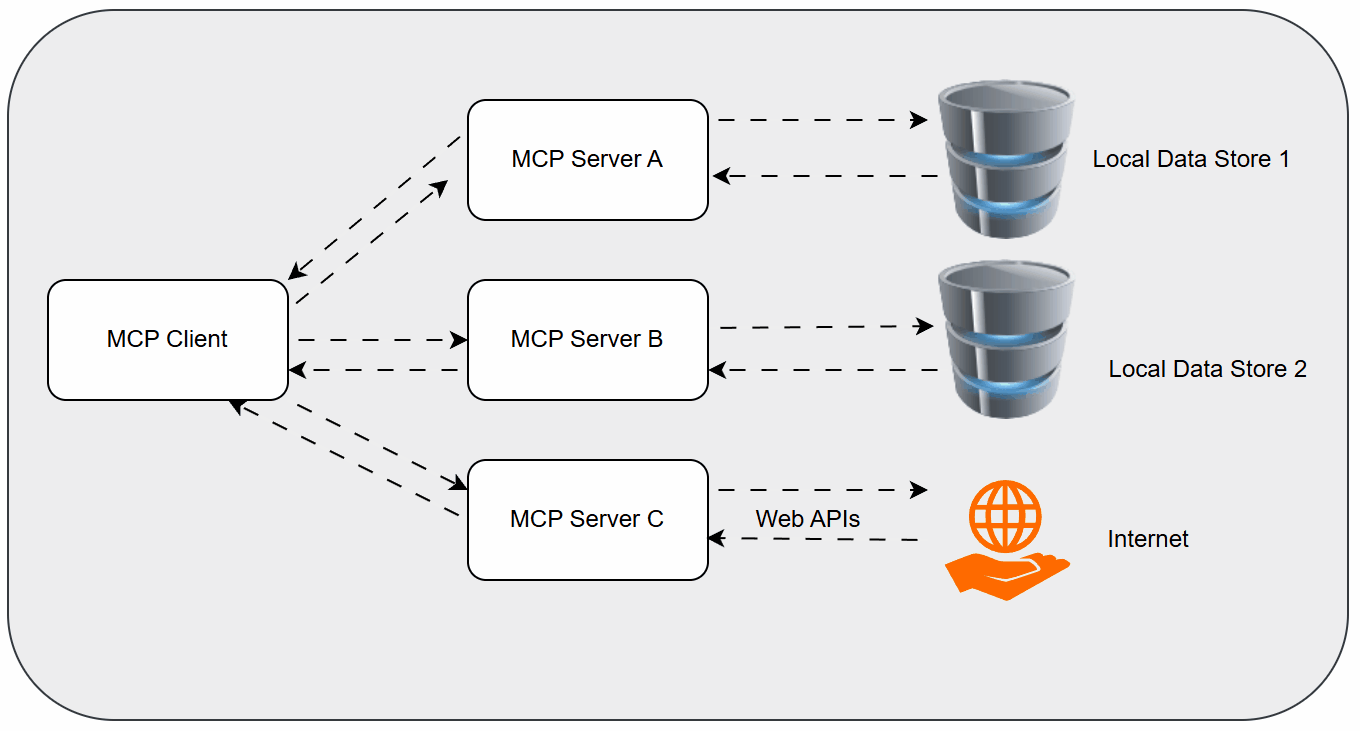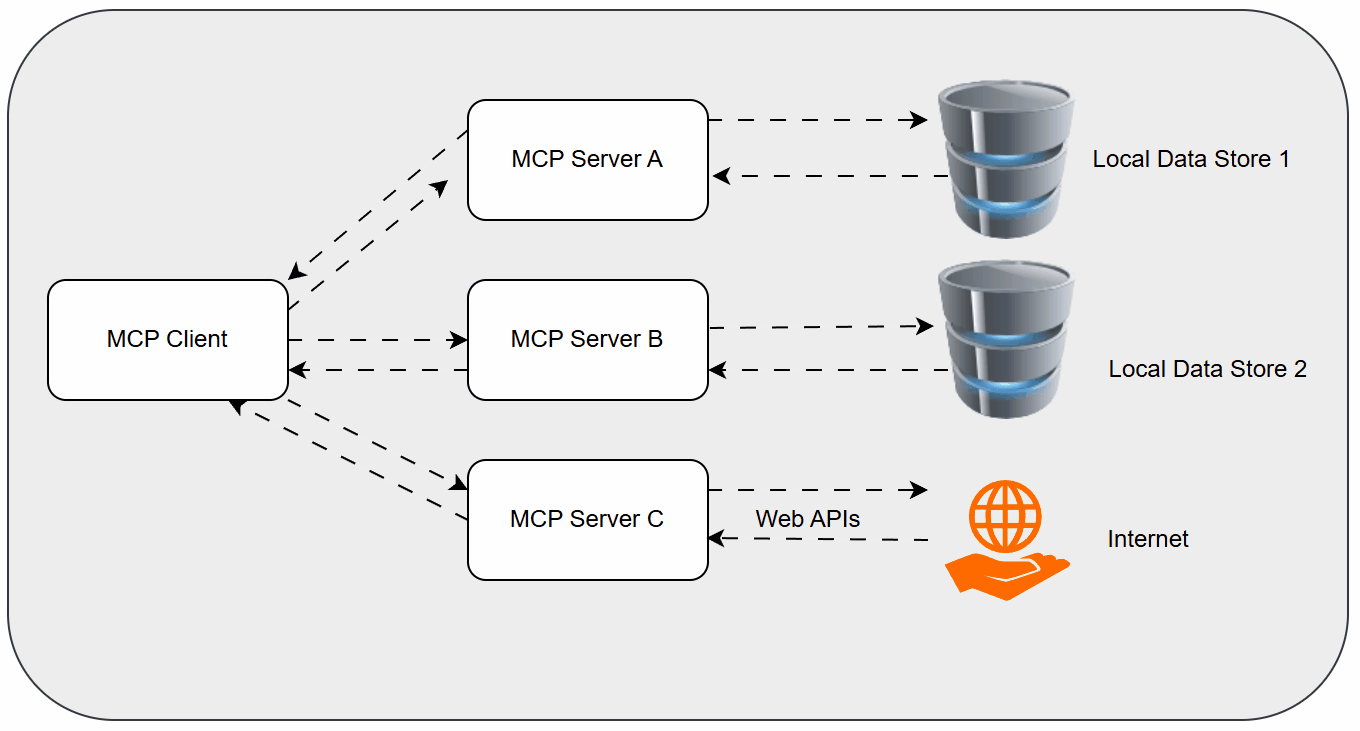
MCP was introduced in late 2023, and companies like Block, Replit, Apollo, and Sourcegraph are already adopting it, signaling its growing importance in the AI ecosystem. For a foundational understanding, you can refer to Wikipedia's entry on the Model Context Protocol.
MCP vs. Traditional API Integrations & Other Frameworks
It's important to distinguish MCP from traditional API integrations and other AI frameworks.
- Traditional API Integrations: These are point-to-point connections. If an LLM needs to use a calculator API, a developer writes code to call that specific calculator API. If it needs to use a weather API, a different piece of code is written. MCP abstracts this away.
- OpenAPI: While OpenAPI defines how to describe an API, MCP defines the protocol for how an AI model should interact with that API (or any tool). MCP focuses on the communication handshake between the AI and the tool.
- Frameworks like LangChain: Frameworks like LangChain provide abstractions and tools for building LLM applications, including agents and tool integration. MCP can be seen as a foundational protocol that such frameworks can leverage to standardize tool interactions. It defines what an AI can do with a tool, while frameworks help orchestrate how the AI decides to do it.
MCP doesn't replace these; it complements them by providing a common language for AI-to-tool communication.
Implementing MCP: A Practical Developer's Guide
Let's move from theory to practice. This section provides a step-by-step guide to building a basic MCP server and client using Python. This will demonstrate how an LLM can be configured to use external tools defined via the MCP.
Setting Up Your Local MCP Environment
First, ensure you have Python installed. You'll need to install a few key libraries:
anthropic: For interacting with Anthropic's Claude models.fastapi: A modern, fast web framework for building APIs.uvicorn: An ASGI server to run your FastAPI application.
You can install them using pip:
pip install anthropic fastapi uvicornBuilding a Simple MCP Server with Function Calling
We'll create a basic FastAPI application that exposes a simple tool – a calculator.
# mcp_server.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import Dict, Any, List
import uvicorn
# Define the structure for tool definitions
class ToolDefinition(BaseModel):
name: str
description: str
parameters: Dict[str, Any]
# Define the structure for an MCP request
class MCPRequest(BaseModel):
tool_code: str # The code to execute (e.g., a function call string)
tools: List[ToolDefinition] # Available tools
# Define the structure for an MCP response
class MCPResponse(BaseModel):
tool_result: Any # The result of the tool execution
app = FastAPI()
# In a real app, this would be more dynamic.
# For simplicity, we'll hardcode a calculator tool.
CALCULATOR_TOOL = ToolDefinition(
name="calculator",
description="A simple calculator tool. Use it to perform arithmetic operations.",
parameters={
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "The arithmetic expression to evaluate (e.g., '2 + 2')."
}
},
"required": ["expression"]
}
)
@app.post("/execute", response_model=MCPResponse)
async def execute_tool(request: MCPRequest):
"""
Executes the tool code provided in the request.
This is a simplified example; a real MCP server would parse tool_code
and map it to actual functions.
"""
try:
# For this example, we'll directly evaluate the expression if it's the calculator tool.
# In a real scenario, you'd parse request.tool_code and call the appropriate function.
if "calculator" in request.tool_code.lower():
# Extract the expression from the tool_code string (very basic parsing)
# Example tool_code: 'calculator(expression="2 + 2")'
expression_start = request.tool_code.find("expression=\"") + len("expression=\"")
expression_end = request.tool_code.find("\"", expression_start)
expression = request.tool_code[expression_start:expression_end]
result = eval(expression) # WARNING: eval is dangerous in production! Use with extreme caution.
return MCPResponse(tool_result=result)
else:
raise HTTPException(status_code=400, detail="Unsupported tool or invalid tool code.")
except Exception as e:
raise HTTPException(status_code=500, detail=f"Error executing tool: {e}")
@app.get("/tools")
async def get_tools():
"""
Returns the list of available tools.
"""
return {"tools": [CALCULATOR_TOOL]}
if __name__ == "__main__":
# To run this server: python mcp_server.py
# Then access http://127.0.0.1:8000/docs for API documentation
uvicorn.run(app, host="127.0.0.1", port=8000)o run this server: Save the code as mcp_server.py and run python mcp_server.py in your terminal. You can then access the API documentation at http://127.0.0.1:8000/docs.
Integrating an LLM Client with Your MCP Server
Now, let's create a Python script that uses the Anthropic API to interact with our MCP server. The LLM needs to be configured with the available tools and then handle the responses from our server.
# mcp_client.py
import anthropic
import requests
import json
# --- Configuration ---
ANTHROPIC_API_KEY = "YOUR_ANTHROPIC_API_KEY" # Replace with your actual key
MCP_SERVER_URL = "http://127.0.0.1:8000"
# --- Initialize Clients ---
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
# --- Helper Functions ---
def get_available_tools():
"""Fetches tool definitions from the MCP server."""
try:
response = requests.get(f"{MCP_SERVER_URL}/tools")
response.raise_for_status() # Raise an exception for bad status codes
return response.json().get("tools", [])
except requests.exceptions.RequestException as e:
print(f"Error fetching tools from MCP server: {e}")
return []
def call_mcp_tool(tool_definition: dict, tool_code: str):
"""Calls the MCP server to execute a tool."""
try:
# Construct the request payload for the MCP server
mcp_payload = {
"tool_code": tool_code,
"tools": [tool_definition] # Pass the specific tool definition being called
}
response = requests.post(f"{MCP_SERVER_URL}/execute", json=mcp_payload)
response.raise_for_status()
return response.json().get("tool_result")
except requests.exceptions.RequestException as e:
print(f"Error calling MCP tool: {e}")
return None
# --- Main Chat Function ---
def chat_with_mcp(user_input: str, history: List[Dict[str, str]] = None):
if history is None:
history = []
# Get tool definitions from the MCP server
available_tools = get_available_tools()
if not available_tools:
print("Warning: Could not retrieve tools. Proceeding without tool use.")
# Fallback to simple chat if tools are unavailable
messages = history + [{"role": "user", "content": user_input}]
response = client.messages.create(
model="claude-3-opus-20240229", # Or another Claude model
max_tokens=1000,
messages=messages
)
ai_response = response.content[0].text
history.append({"role": "user", "content": user_input})
history.append({"role": "assistant", "content": ai_response})
return ai_response, history
# Prepare messages for the LLM, including tool definitions
messages = history + [{"role": "user", "content": user_input}]
try:
# First call to LLM to determine if a tool should be used
response = client.messages.create(
model="claude-3-opus-20240229", # Or another Claude model
max_tokens=1000,
messages=messages,
tools=available_tools # Pass tool definitions to the LLM
)
# Check if the LLM wants to use a tool
if response.stop_reason == "tool_use":
tool_use_block = response.content[0]
tool_name = tool_use_block.tool_use.name
tool_input = tool_use_block.tool_use.input
tool_use_id = tool_use_block.tool_use.id
# Find the corresponding tool definition
tool_definition = next((tool for tool in available_tools if tool["name"] == tool_name), None)
if tool_definition:
print(f"LLM wants to use tool: {tool_name} with input: {tool_input}")
# Call the MCP server to execute the tool
tool_result = call_mcp_tool(tool_definition, f'{tool_name}(expression="{tool_input.get("expression")}")') # Simplified tool_code generation
if tool_result is not None:
print(f"Tool result: {tool_result}")
# Second call to LLM with the tool result
messages.append({
"role": "user",
"content": [
{
"type": "tool_use_block",
"name": tool_name,
"id": tool_use_id,
"input": tool_input
}
]
})
messages.append({
"role": "user", # Role is 'user' for tool results in Anthropic's API structure
"content": [
{
"type": "tool_result",
"tool_use_id": tool_use_id,
"content": tool_result
}
]
})
response = client.messages.create(
model="claude-3-opus-20240229", # Or another Claude model
max_tokens=1000,
messages=messages
)
ai_response = response.content[0].text
else:
ai_response = "Sorry, I encountered an error trying to use the tool."
else:
ai_response = f"Sorry, I don't know how to use the tool '{tool_name}'."else:
# No tool use, just a regular text response
ai_response = response.content[0].text
# Update history
history.append({"role": "user", "content": user_input})
history.append({"role": "assistant", "content": ai_response})
return ai_response, history
except Exception as e:
print(f"An error occurred: {e}")
return "An error occurred. Please try again.", history
# --- Example Usage ---
if __name__ == "__main__":
# Ensure your MCP server (mcp_server.py) is running!
print("Starting chat with MCP client...")
chat_history = []
while True:
user_input = input("You: ")
if user_input.lower() in ["quit", "exit", "bye"]:
break
ai_response, chat_history = chat_with_mcp(user_input, chat_history)
print(f"AI: {ai_response}")
print("Chat session ended.")To run this client:
- Make sure your
mcp_server.pyis running. - Replace
"YOUR_ANTHROPIC_API_KEY"with your actual Anthropic API key. - Run
python mcp_client.pyin your terminal.
Now you can interact with the AI. Try prompts like:
- "What is 2 + 2?"
- "Calculate 10 * (5 - 3)"
- "Tell me a joke." (This should result in a normal text response as it doesn't require the calculator tool).
This example demonstrates the core loop: the LLM identifies a need for a tool, the client calls the MCP server, the result is returned to the LLM, and the LLM generates a final response based on the tool's output.
Scaling Up: MCP in Production Environments (e.g., AWS)
For production environments, you'll want to deploy your MCP server and LLM client more robustly.
- Server Deployment: Your FastAPI MCP server can be deployed using services like AWS Lambda, Google Cloud Functions, or containerized solutions like Docker on AWS ECS/EKS or Google Kubernetes Engine. This provides scalability and reliability.
- LLM Integration: When using managed LLM services like Amazon Bedrock, you can often configure custom model integrations or leverage their built-in tool-use capabilities, which may align with or be adaptable to MCP standards.
- Security: In a production setting, securing your MCP endpoint is crucial. This involves proper authentication and authorization mechanisms, ensuring only authorized LLM clients can invoke your tools.
- Monitoring and Logging: Implement comprehensive logging for both the MCP server and the LLM client to track tool usage, identify errors, and monitor performance.
For a detailed guide on deploying MCP in AWS environments, refer to Unlocking the Power of Model Context Protocol (MCP) on AWS.
Conclusion
The promise of Artificial Intelligence is immense, but its practical realization hinges on our ability to manage context. The inherent statelessness of LLMs, coupled with context window limitations and the risk of inaccuracies, presents significant challenges for developers.
We've explored the "context crisis," from the fundamental stateless nature of LLMs to the practical implications of context window limits and hallucinations. We've introduced a Maturity Model for Context Management, guiding you from basic history buffers to sophisticated state machines and memory architectures.
Mastering AI context is no longer an optional consideration; it's a prerequisite for building reliable, scalable, and intelligent AI systems. By embracing structured context, leveraging protocols like MCP, and employing holistic strategies for model accuracy, you can move beyond the limitations of basic prompt engineering and unlock the true potential of AI.
Start experimenting with MCP today. Implement the code provided, explore the official MCP documentation, and begin transforming your AI applications into context-aware powerhouses. The future of AI is contextual, and MCP is paving the way.
References
- Anthropic. (N.D.). Claude API Documentation. Retrieved from Anthropic API Documentation.
- AWS. (2024). Unlocking the Power of Model Context Protocol (MCP) on AWS. AWS Machine Learning Blog.
- Karpathy, A. (2024). Context Engineering. (Conceptual reference based on research summary).
- Google AI for Developers. (N.D.). Long context | Gemini API. Retrieved from Google AI for Developers.
- KeywordsAI.co. (2025). A Complete Guide to the Model Context Protocol (MCP) in 2025. Retrieved from KeywordsAI.co.
- PMC/NCBI. (2023). Understanding and Addressing Inaccurate, Misleading Outputs from AI Models. (Conceptual reference to research on AI hallucinations).
- Perplexity AI. (N.D.). Context Window Limitations of LLMs. Retrieved from Perplexity AI.
- TowardsAI. (2024). The Complete Guide to Context Engineering Framework for Large Language Models. Retrieved from TowardsAI.
- Wikipedia. (N.D.). Model Context Protocol. Retrieved from Wikipedia.
Inspire Others – Share Now
Agentic AI Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own AI Agents
EV
Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own vehicle
Agentic AI LeadCamp
From AI User to AI Agent Builder — Capabl empowers non-coding professionals to ride the AI wave in just 4 days.
Agentic AI MasterCamp
A complete deployment ready program for Developers, Freelancers & Product Managers to be Agentic AI professionals

.png)
Table of Contents
1.1. The Rise of LLMs and Their Limitations
1.2. Why Context Matters in AI Applications
2.1. The Stateless Nature of LLMs
2.2. The Context Window Bottleneck
2.3. Hallucinations and Inaccuracies Caused by Missing Context
3.1. What Is Context in AI?
3.2. Types of Context: Conversation, Knowledge, and Instructions
3.3. Token Limits and Model Constraints
4.1. Level 1: Basic Context Storage (History Buffers)
4.2. Level 2: Structured Context and State Machines
4.3. Level 3: Advanced Context with Memory Architectures & Agents
5.1. What Is the Model Context Protocol?
5.2. Why MCP Is a Game-Changer
5.3. MCP vs Traditional API Integrations
5.4. How MCP Complements Frameworks like LangChain and OpenAPI
6.1. Setting Up the Local Development Environment
6.2. Building a Simple MCP Server (Python + FastAPI)
6.3. Integrating an LLM Client with MCP
6.4. Handling Tool Calls and Responses
7.1. Structuring Context for Maximum Efficiency
7.2. Preventing Token Overflow and Forgetting
7.3. Debugging and Monitoring Context Flows
8.1. Building Stateful AI Agents
8.2. Knowledge Retrieval and RAG Systems
8.3. AI Applications in Enterprises
9.1. Standardization and Ecosystem Growth
9.2. Interoperability Across Models and Tools
9.3. Opportunities for Developers and Startups
10.1. Key Takeaways
10.2. Why Context Is the Next Frontier in AI
10.3. Resources and Further Reading



