
Anthropic recently dropped a brilliant update on their Model Context Protocol (MCP) that, honestly, feels like a massive leap forward. It’s a big shift in philosophy: moving their agents from a clumsy "direct tool call" system to letting the agent write actual code to interact with the world.
It's a huge upgrade, and a necessary one. Here’s why and how it differs from the old way.
The Pain Points of the 'Old' Way (Direct Tool Calls)
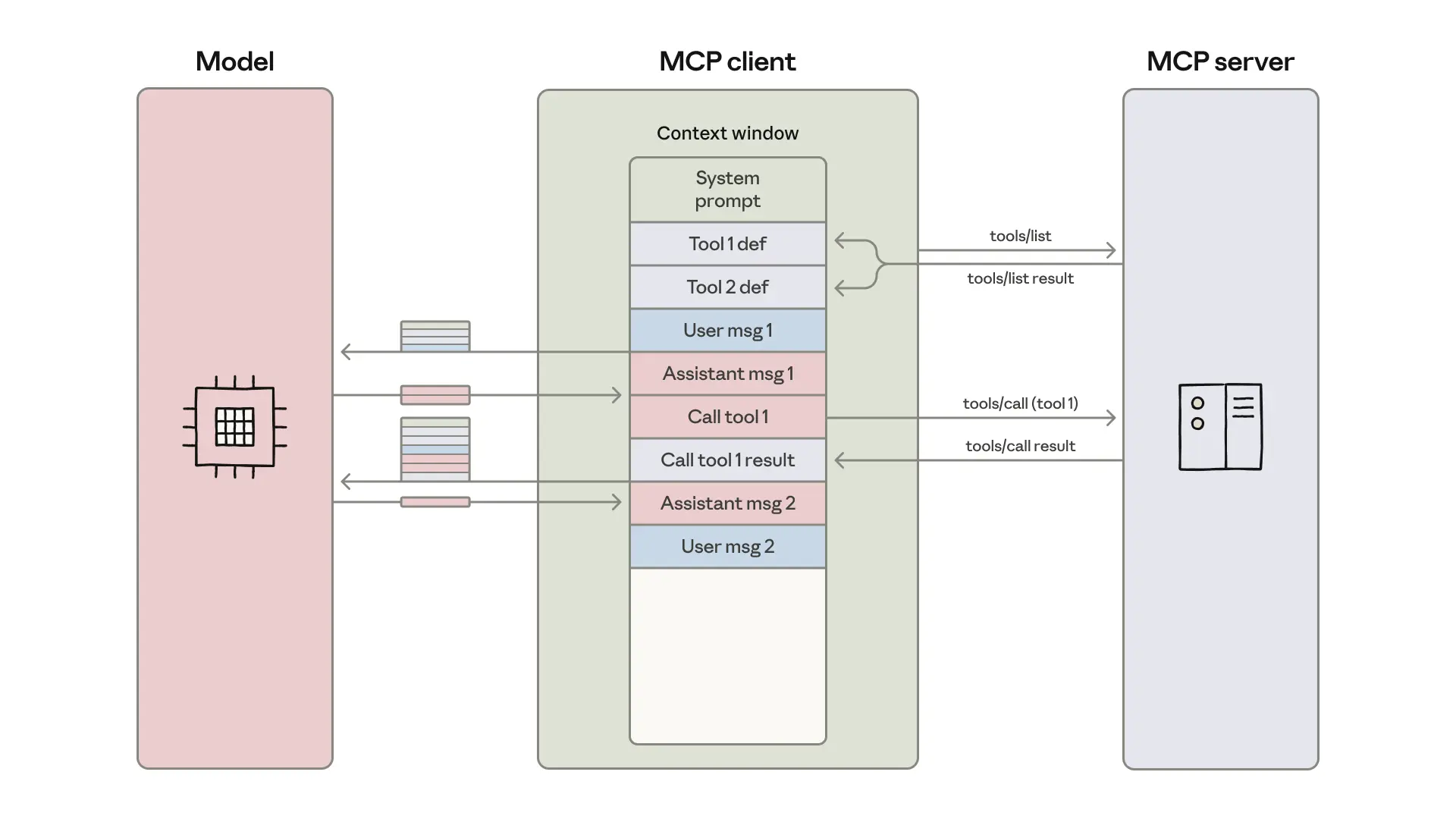
Okay, so how did it work before, using the original standard for connecting an AI to a tool? It worked, to be fair, but it was inefficient. The traditional method was based on a simple message loop, which meant the model was constantly getting overloaded with information.
1. Tool Definitions Clogging the Context
The old approach typically meant exposing all available tools to the LLM by dumping their full definitions, descriptions, parameters, return schemas right into the context window before the agent even read the user’s request.
Just imagine: your agent is connected to, say, a thousand different internal tools across dozens of services. You're chewing up hundreds of thousands of tokens just so the model knows what it can do, before it starts the job. It’s pure overhead, and it makes the entire process slower and significantly more expensive. Talk about context claustrophobia, ugh.
2. The Data Delivery Problem
Worse still, when the model successfully called a tool, the entire result had to flow back through the model's context window.
For example, if you asked the agent to "Download my meeting transcript and attach it to the Salesforce lead," the full transcript text (which could be 50,000 tokens for a two-hour meeting)would flow into the model's context. Then, the model would have to write that entire transcript again into the next tool call for Salesforce. The model was acting as a high-priced, easily-distracted delivery person, simply shuttling massive amounts of data from Tool A to Tool B. This not only wastes tokens but also introduces a higher risk of the model making mistakes when copying large, complex data structures.
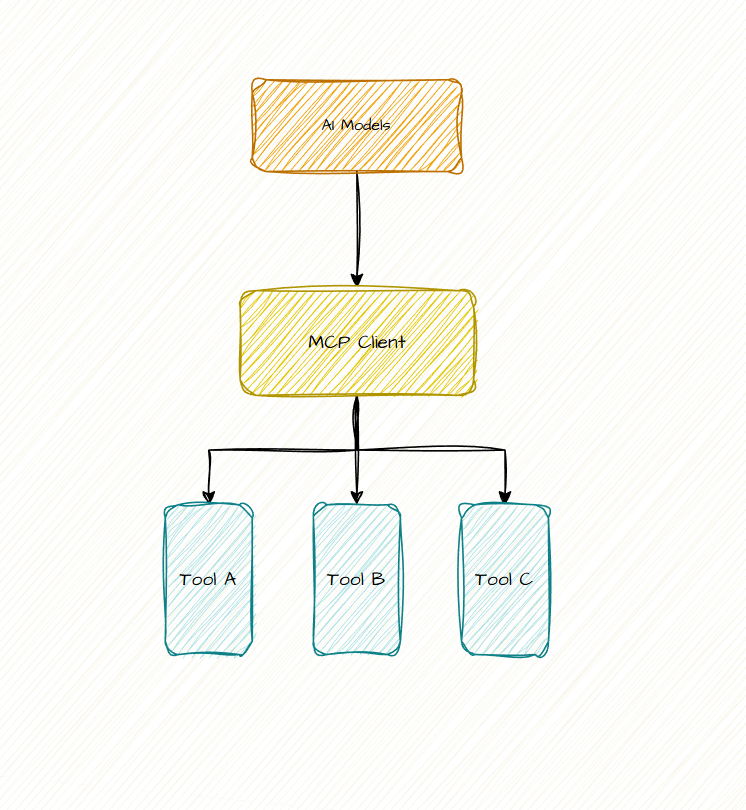
The Brilliant Shift to Code Execution with MCP
The new approach is brilliant because it leverages the LLM's greatest strength: its ability to write code.
Instead of seeing a list of functions in its context, the agent now sees the MCP servers as actual code APIs on a filesystem. We’re talking a simple file tree structure like /servers/google-drive/getDocument.ts and /servers/salesforce/updateRecord.ts. The agent’s job shifts from merely selecting a function to writing a small, standard script to accomplish the goal.
This is the fundamental difference, and it has incredible cascading benefits.
1. Progressive Disclosure: Loading Tools On-Demand
This is the huge token-saving mechanism. The agent no longer has to load every single tool definition upfront. It can now explore the virtual filesystem, or use a specific search_tools function, to only read the one or two definitions it needs for the current task.
In Anthropic’s example, this simple change can cut token usage from 150,000 down to 2,000 for a complex task. That's a massive, nearly 99% saving in time and cost. It’s like switching from carrying a library's entire catalog around to just pulling the single index card you need for the one book you want.
2. Smart Processing in the Execution Environment
Here’s my favorite part: the data stays where it belongs.
With code execution, the LLM writes the script, but the filtering, processing, and aggregation of data happens within the secure code execution environment, outside of the model’s context.
Say you need to fetch a 10,000-row spreadsheet to find pending orders. The agent writes a script to fetch the data and then uses a standard array method like .filter(row => row["Status"] === 'pending'). The LLM only sees the final result, maybe a printout of the five pending orders not all 10,000 rows. This is efficient, keeps the model focused, and prevents the context window from breaking.
3. Security and State Persistence
Code execution also solves problems the old system couldn't easily handle:
- Privacy: Since intermediate results stay in the execution environment, sensitive data (like full email addresses or phone numbers) can be tokenized or completely bypass the model’s context window on its way from Tool A to Tool B. This means the model only sees
[EMAIL_1]instead of the actual address, which is a massive win for data privacy and security compliance. - Control Flow: Need a loop, a conditional, or error handling? You don’t have to chain together clumsy, token-heavy tool calls anymore. You just write the
while (!found)loop or theif/elseblock right in the agent's code, just like a human programmer would. - Skill Building: Agents can now save working code as reusable Skills on the filesystem. Once they figure out the best way to do something, they write it to a file, and they can import that function later. This lets the agent build its own toolbox of higher-level capabilities, evolving its own scaffold for success.
Final Thoughts
The core insight here is that LLMs are really good at writing code. So why force them to use a custom, token-heavy protocol when they could be using standard, powerful programming constructs?
This move to code execution with MCP isn't just about saving tokens (though that’s a huge plus for efficiency and cost). It's about building agents that are more capable, more secure, and infinitely more scalable. It's taking software engineering’s best practices, like progressive disclosure and local data processing, and applying them directly to the world of AI agents. It just makes so much sense, to be honest. It feels like the true future of tool use.
Inspire Others – Share Now
Agentic AI Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own AI Agents
EV
Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own vehicle
Agentic AI LeadCamp
From AI User to AI Agent Builder — Capabl empowers non-coding professionals to ride the AI wave in just 4 days.
Agentic AI MasterCamp
A complete deployment ready program for Developers, Freelancers & Product Managers to be Agentic AI professionals

.png)
Table of Contents
I. The Pain Points of the 'Old' Way (Direct Tool Calls)
1. Tool Definitions Clogging the Context
2. The Data Delivery Problem
II. The Brilliant Shift to Code Execution with MCP
1. Progressive Disclosure: Loading Tools On-Demand
2. Smart Processing in the Execution Environment
3. Security and State Persistence
III. Final Thoughts



