

What Exactly Is DSPy? And Why Do We Need It?
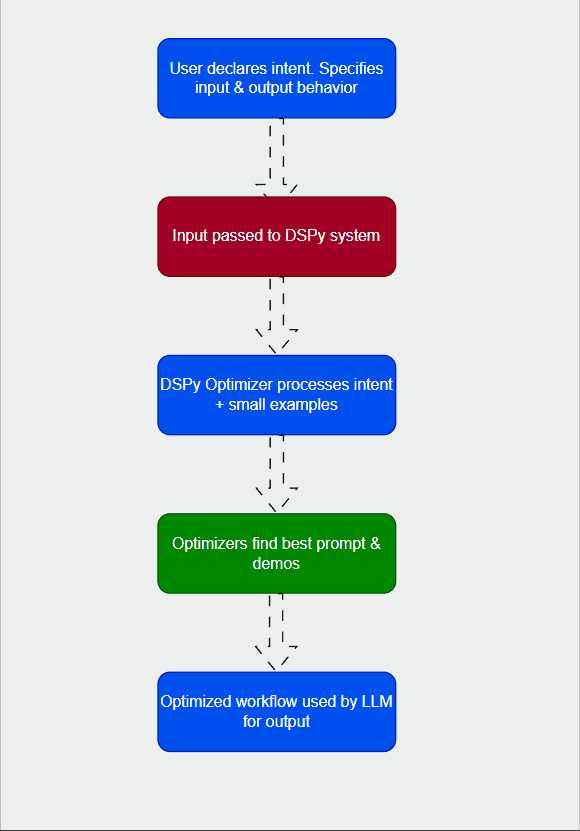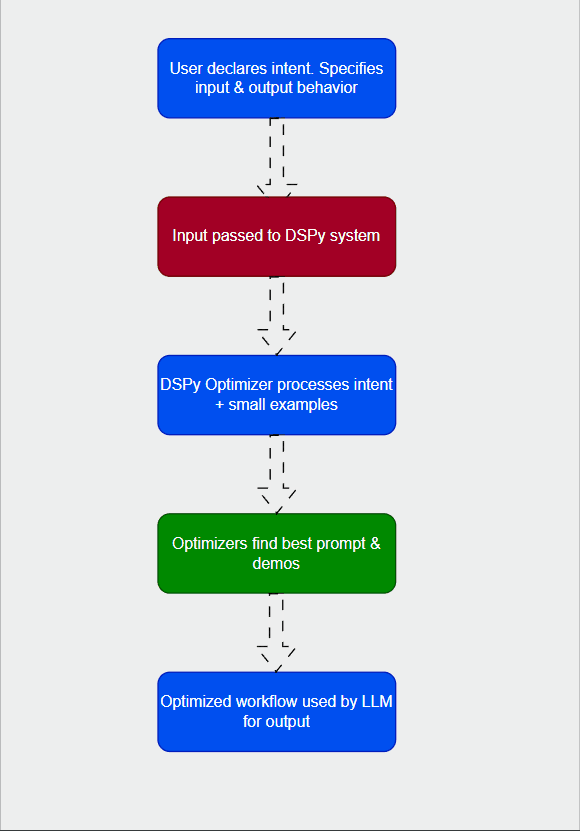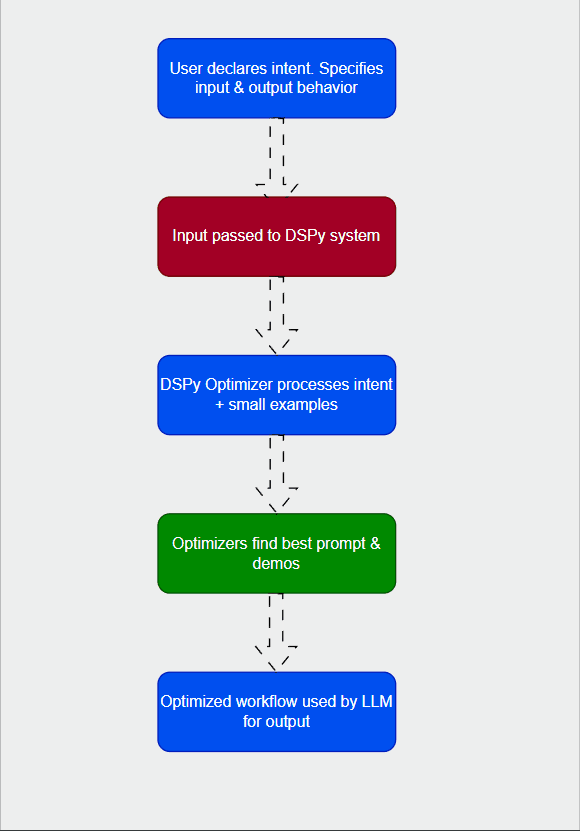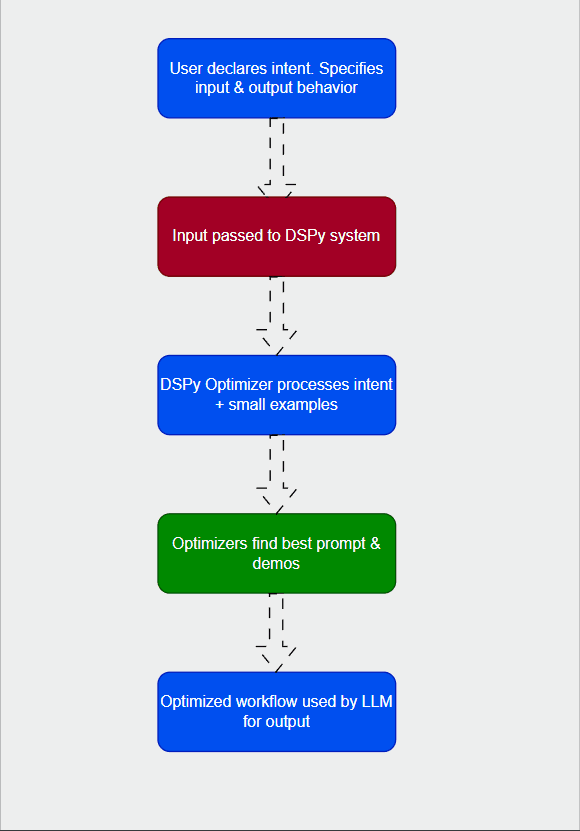
DSPy is a framework designed to make LLM development more robust, efficient, and, crucially, self-improving. Think of it this way: instead of you manually crafting every single prompt, DSPy allows you to declare the behavior you want from your LLM. You tell it what to achieve, and DSPy figures out the how.
The "self-improving" part is really the game-changer. DSPy can automatically optimize the prompts, weights, and even the structural components of your language model pipeline to achieve better results on a given task, based on a dataset of examples. It's like having an expert prompt engineer working tirelessly in the background, constantly refining your system.
- Reduces Manual Prompt Engineering: Seriously, who enjoys endless prompt tweaking? DSPy automates much of this, freeing up developers to focus on higher-level logic.
- Improves Performance & Robustness: By systematically optimizing prompts and model usage, DSPy often leads to more accurate and reliable outputs compared to handcrafted prompts.
- Enhances Modularity and Readability: It provides a structured way to build complex LLM applications, making them easier to understand, maintain, and debug.
- Adapts to New Models & Tasks: Because the "how" is learned, your DSPy program can often adapt more easily if you swap out an LLM or want to tackle a slightly different task.
The Core Philosophy: Declaring Your Intent
The fundamental idea behind DSPy is to separate the "what" from the "how."
- You Declare: You specify the desired input-output behavior of your LLM application. For instance, "I want to take a question and an article, and output an answer." You don't specify the exact prompt for the LLM to achieve this.
- DSPy Optimizes: DSPy then uses an optimizer to learn the best way to prompt the LLM, select demonstrations, or even re-arrange computational steps to fulfill your declared goal. This optimization happens on a small set of examples, almost like a mini-training phase.
This declarative approach is powerful because it allows you to express complex multi-step reasoning without getting bogged down in the minutiae of individual prompt construction.
DSPy's Building Blocks: Modules, Signatures, and Optimizers
To understand how DSPy works, let's look at its main components:
- Signatures: This is where you declare your intent. A signature defines the input and output fields for a specific task you want an LLM to perform. Think of it like a function signature in Python, but for an LLM.
import dspy
class GenerateAnswer(dspy.Signature):
"""Generates an answer to a question based on provided context."""
context: str = dspy.InputField(desc="Relevant context for the question.")
question: str = dspy.InputField(desc="The question to be answered.")
answer: str = dspy.OutputField(desc="The concise answer to the question.")You're not saying how to prompt for it. You're just saying: "Hey, give me an answer from context and a question." No prompt here, just the desired inputs and outputs.
- Modules: DSPy modules are like neural network layers, but for LLM operations. They encapsulate different ways an LLM can be used, such as answering a question, generating text, or performing multi-step reasoning. Modules take a
Signatureas input.
# This setup is usually done once at the beginning of your script
llm = dspy.OpenAI(model='gpt-3.5-turbo', max_tokens=250)
dspy.configure(lm=llm)
# Now, we can instantiate a Predict module with our signature
# Predict is a basic module that takes a signature and gets an LLM to fulfill it
generate_answer_module = dspy.Predict(GenerateAnswer)
# Example usage:
context_text = "DSPy is a framework for optimizing LLM programs. It enables declarative prompt engineering."
my_question = "What is DSPy?"
prediction = generate_answer_module(context=context_text, question=my_question)
print(prediction.answer)This Predict module, behind the scenes, will figure out how to best prompt the llm to generate an answer based on the context and question you provide.
There are also other modules for more complex operations, like dspy.ChainOfThought (which prompts the LLM to think step-by-step) and dspy.Retrieve (for RAG-like functionalities).
- Optimizers (Teleprompters): This is the "self-improving" part. Optimizers are algorithms that take your DSPy program (which is essentially a collection of modules and signatures) and a small dataset of examples, and then automatically tune the internal prompts and demonstrations used by each module to maximize performance on your task.
trainset = [
{'context': 'DSPy is a framework for optimizing LLM programs. It enables declarative prompt engineering.',
'question': 'What is DSPy?',
'answer': 'DSPy is a framework for optimizing LLM programs that enables declarative prompt engineering.'},
# ... more examples
]
# And a metric to evaluate how good the answer is
def my_metric(prediction, actual_answer, *args):
# A simple placeholder metric: check if actual answer is in predicted answer
return actual_answer.lower() in prediction.answer.lower()
# Now, let's use a basic optimizer: BootstrapFewShot
# This optimizer learns effective prompts and few-shot examples from your training set.
optimizer = dspy.BootstrapFewShot(metric=my_metric)
optimized_program = optimizer.compile(generate_answer_module, trainset=trainset)DSPy vs. Traditional Prompting & Direct LLM Calls
This is a crucial distinction.
Traditional Prompting: You write a prompt like: "Given the following context: [CONTEXT]. Answer the question: [QUESTION]. Be concise." You then feed this directly to the LLM. If the performance isn't great, you manually tweak the prompt, add examples, or change instructions. It's often trial and error.
Direct LLM Calls: This is just using llm.invoke("Your meticulously crafted prompt here"). No framework, just raw API calls. Very flexible, but also very manual and scales poorly.
DSPy's Approach: You declare a Signature (e.g., (context, question) -> answer). You wrap this in a Module (e.g., dspy.Predict). Then, you use an Optimizer with a small dataset to automatically generate and refine the actual prompts and examples used by the LLM within that module. You never see or manually edit the final prompt the LLM receives. DSPy handles it for you. This makes your system more robust to changes in the underlying LLM or minor shifts in task requirements.
DSPy in RAG and Fine-tuning
- DSPy's Synergy with RAG: DSPy can incorporate RAG directly into its pipelines. In fact, DSPy has a
dspy.Retrievemodule! You can declare a signature for retrieval (e.g.,(query) -> relevant_documents), usedspy.Retrieveas a module, and then have DSPy optimize how your retrieval query is formed and how the retrieved documents are then used by a subsequent generation module. DSPy can essentially optimize your entire RAG pipeline, not just the generation part.
- DSPy's Relationship to Fine-tuning: DSPy is generally an alternative to, or complement for, fine-tuning. It focuses on optimizing how you use an existing frozen LLM, rather than changing its internal weights. This makes it much faster and cheaper than fine-tuning. For many tasks, DSPy can achieve fine-tuning-like performance improvements just by intelligently optimizing prompts and few-shot examples, without ever touching the model's weights. You can even use DSPy with a fine-tuned LLM if you wish, getting the best of both worlds.
DSPy is flexible enough to integrate these techniques. You can have a DSPy program that includes both retrieval modules and generation modules, with optimizers tuning the entire flow.
Hands-on: Building a Simple Question Answering System with RAG and DSPy
import dspy
from dspy.teleprompt import BootstrapFewShot
# 1. Configure your Language Model and Retriever (e.g., using OpenAI and a simple simulated retriever)
# In a real app, 'my_retriever' would be connected to a vector database like Pinecone, Weaviate, etc.
# Let's use a dummy retriever for demonstration
class DummyRetriever(dspy.Retrieve):
def __init__(self, k=3):
super().__init__(k=k)
self.documents = [
"DSPy enables declarative prompt engineering.",
"It optimizes LLM programs for better performance.",
"Traditional prompt engineering is often manual and slow.",
"Retrieval-Augmented Generation (RAG) combines retrieval with LLMs.",
"Fine-tuning changes LLM weights, DSPy optimizes usage.",
"Agentic AI systems benefit from self-improving components like DSPy.",
]
def forward(self, query):
# In a real retriever, this would query a vector DB.
# Here, we just do a simple keyword search.
results = [doc for doc in self.documents if query.lower() in doc.lower()]
# For simplicity, let's just return docs containing the query, up to k
return dspy.Prediction(
passages=[dspy.Doc(text=doc) for doc in results[:self.k]]
)
llm = dspy.OpenAI(model='gpt-3.5-turbo', max_tokens=250)
retriever = DummyRetriever(k=2) # Get top 2 "relevant" docs
dspy.configure(lm=llm, rm=retriever)
# 2. Define the DSPy Signature for our QA task
class GenerateAnswer(dspy.Signature):
"""Answers questions based on retrieved context."""
context: str = dspy.InputField(desc="Retrieved context passages.")
question: str = dspy.InputField(desc="The user's question.")
answer: str = dspy.OutputField(desc="The concise, factual answer.")
# 3. Build a DSPy Program (a multi-stage 'module')
class RAG(dspy.Module):
def __init__(self):
super().__init__()
self.retrieve = dspy.Retrieve(k=3) # Use the configured retriever
self.generate_answer = dspy.ChainOfThought(GenerateAnswer) # Use CoT for better reasoning
def forward(self, question):
# First, retrieve relevant context
context = self.retrieve(question).passages
# Then, use ChainOfThought to generate an answer based on the context and question
prediction = self.generate_answer(context=context, question=question)
return prediction
# Instantiate our RAG program
my_rag_program = RAG()
# 4. Prepare a tiny dataset and metric for optimization
trainset = [
dspy.Example(question="What does DSPy help with?", answer="DSPy helps optimize LLM programs for better performance and reduces manual prompt engineering."),
dspy.Example(question="How is DSPy different from fine-tuning?", answer="DSPy optimizes LLM usage without changing model weights, unlike fine-tuning."),
# Add more examples for robust optimization
]
def qa_metric(gold, pred, trace=None):
# A simple metric: check if the answer is roughly correct
# In a real app, this would be more sophisticated (e.g., ROUGE, BLEU, or an LLM judge)
return gold.answer.lower() in pred.answer.lower()
# 5. Optimize the RAG program using BootstrapFewShot
# This will automatically find good prompts and few-shot examples for both retrieve and generate_answer steps
optimizer = BootstrapFewShot(metric=qa_metric)
optimized_rag = optimizer.compile(my_rag_program, trainset=trainset)
# 6. Use the optimized program
question = "What is RAG?"
prediction = optimized_rag(question=question)
print(f"Question: {question}")
print(f"Predicted Answer: {prediction.answer}")
# You can also inspect the internal steps taken by the optimized program
print(f"\nTrace: {optimized_rag.inspect_history(n=1)}")This example shows how DSPy allows you to define a multi-step process (retrieve, then generate) and then optimize the entire pipeline automatically. The BootstrapFewShot optimizer learns good retrieval queries and effective generation prompts based on your training examples, drastically cutting down on manual tuning.
DSPy in the Agentic AI Development
Agentic AI systems are designed to perform complex tasks by breaking them down into sub-problems, using tools, and iteratively refining their approach. They often involve multiple LLM calls and decision points. DSPy improves agentic AI by:
Imagine an agent that needs to research a topic, summarize findings, and then answer follow-up questions. Each of these could be a DSPy module, and the entire agentic workflow could be optimized by DSPy to perform better.
The Future Potential and Real-World Applications
DSPy is still evolving, but its potential is immense. We're moving towards a future where AI systems are not just capable, but also adaptable and self-improving right out of the box.
Real-world applications could include:
- Customer Support Bots: Bots that learn to answer complex queries more accurately and provide better solutions over time.
- Content Generation & Curation: Systems that adapt their writing style or content selection based on user engagement and feedback.
- Automated Data Analysis: Agents that can intelligently query databases, summarize findings, and generate reports, constantly improving their analytical capabilities.
- Code Generation & Refactoring: Tools that learn to generate more correct and efficient code, or refactor existing code more intelligently.
- Personalized Learning Systems: AI tutors that adapt their teaching methods and content explanations based on student performance.
The biggest takeaway here is that DSPy empowers developers to build more sophisticated, reliable, and intelligent LLM applications without getting lost in the weeds of manual prompt engineering. It's a significant step towards truly programmatic and self-optimizing AI. If you're building with LLMs, DSPy is definitely a framework you'll want in your toolkit. It really does change the game.
Inspire Others – Share Now
Agentic AI Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own AI Agents
EV
Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own vehicle
Agentic AI LeadCamp
From AI User to AI Agent Builder — Capabl empowers non-coding professionals to ride the AI wave in just 4 days.
Agentic AI MasterCamp
A complete deployment ready program for Developers, Freelancers & Product Managers to be Agentic AI professionals

.png)
Table of Contents
- What Exactly Is DSPy? And Why Do We Need It?
- The Core Philosophy: Declaring Your Intent
- DSPy's Building Blocks: Modules, Signatures, and Optimizers
- DSPy vs. Traditional Prompting & Direct LLM Calls
- DSPy in RAG and Fine-tuning
- Hands-on: Building a Simple Question Answering System with RAG and DSPy
- DSPy in the Agentic AI Development
- The Future Potential and Real-World Applications



