

The way humans interact with technology is continually evolving, with voice-based interfaces rapidly moving from a novel curiosity to a primary mode of interaction. Google's development of Speech-to-Retrieval (S2R) marks a significant architectural and philosophical change in how machines process spoken queries. This article explains S2R, positioning it as an advancement that moves beyond traditional reliance on text transcription and focuses instead on direct semantic understanding, yielding faster, more robust, and globally inclusive voice search capabilities.
Introduction to Speech-to-Retrieval (S2R)
Speech-to-Retrieval (S2R) is a contemporary technology developed by Google that fundamentally redesigns the workflow for voice search. Historically, voice assistants required an intermediary step of converting spoken words into a text transcript before a search could be executed. S2R, conversely, directly interprets the meaning and intent of the raw audio input and uses this interpretation to retrieve relevant information from a search index.
In essence, S2R shifts the core question for the search engine from: "What exact words were spoken?" to the more profound: "What information is the user seeking?" This direct approach minimizes the reliance on a perfect word-for-word transcription, thereby reducing errors and enhancing the efficiency and reliability of the voice search experience.
Evolution of Voice Search Technology
To appreciate the innovation of S2R, one must understand the foundation upon which it is built. Early voice search systems were designed using a cascade model, a sequential process comprising two main stages:
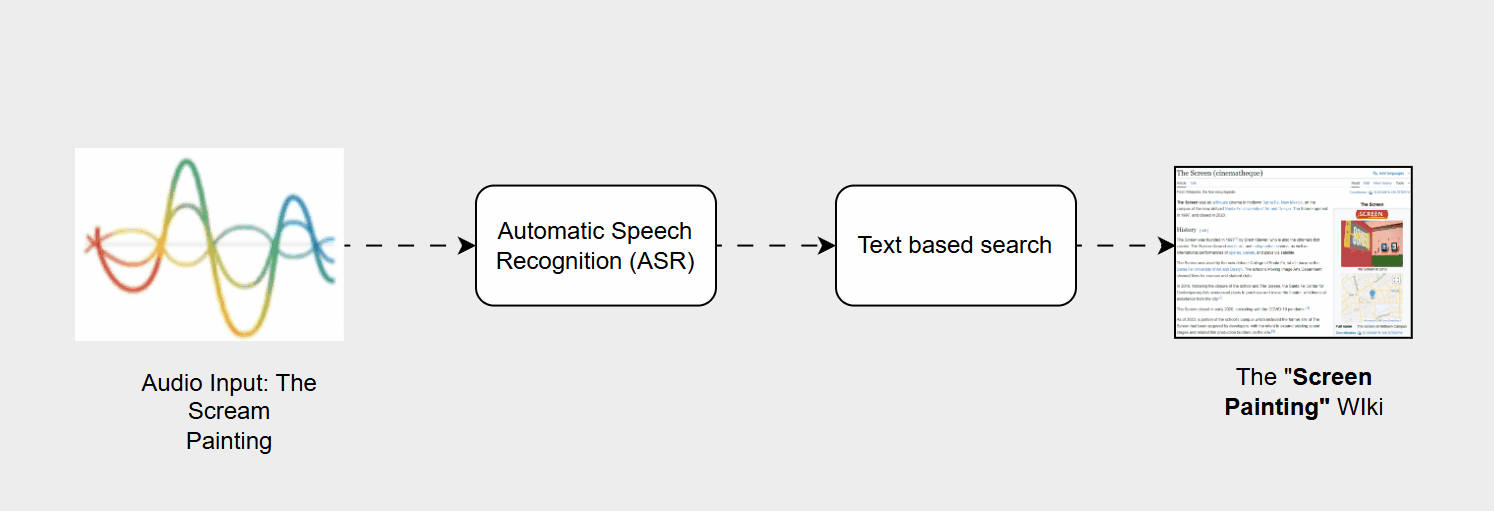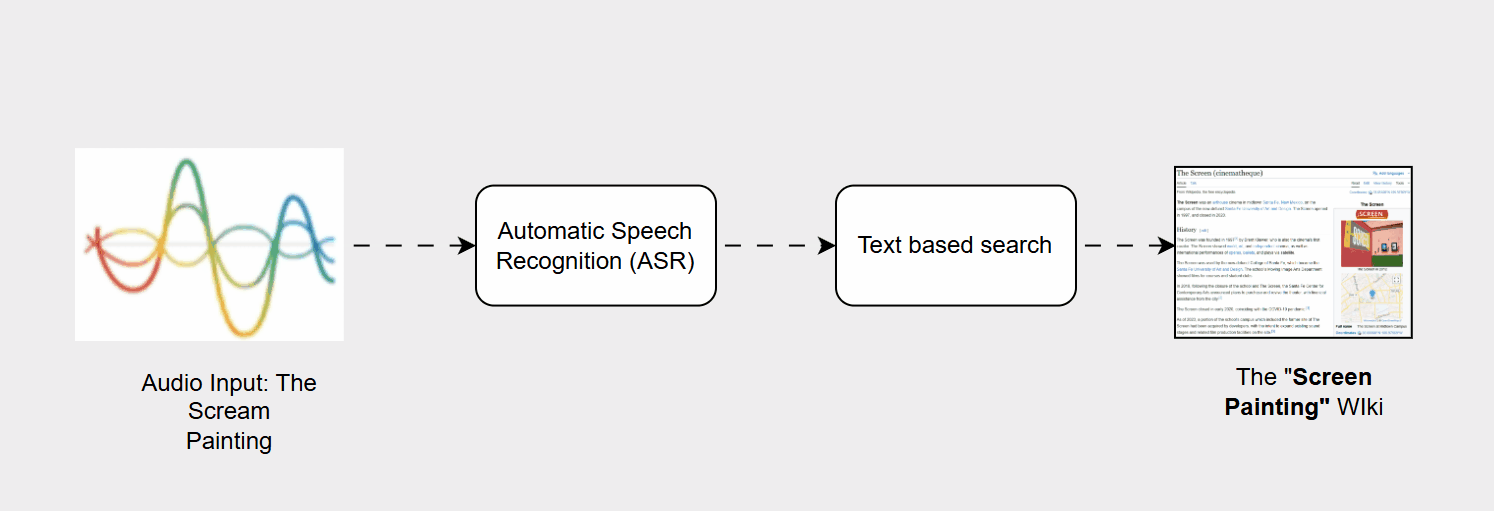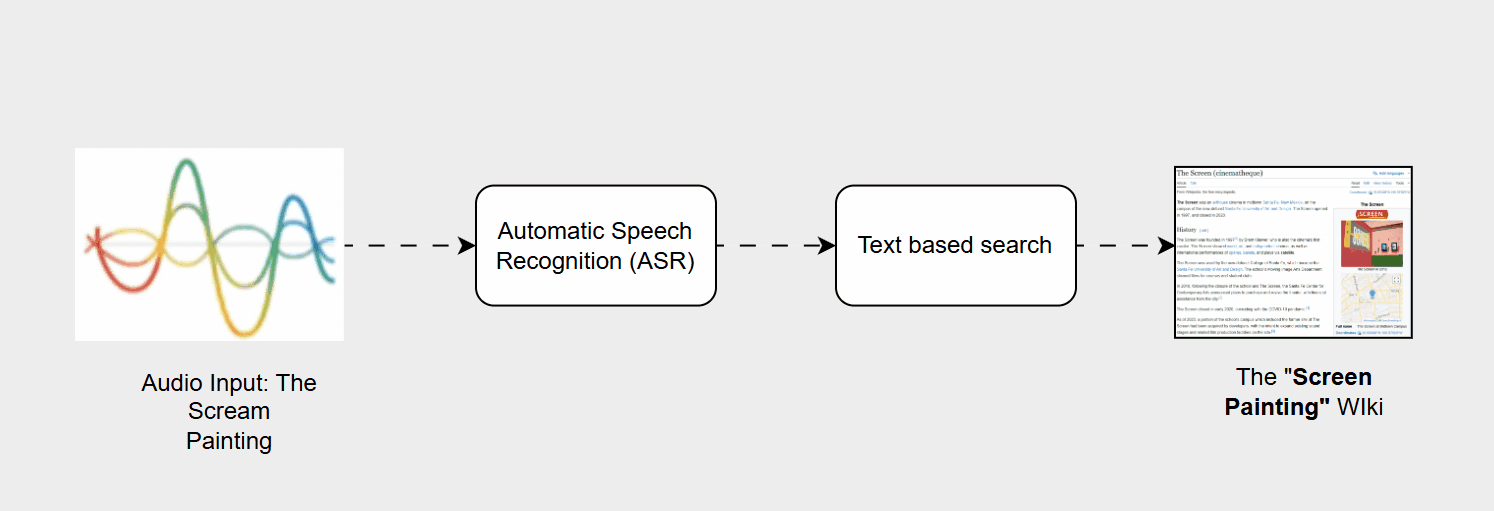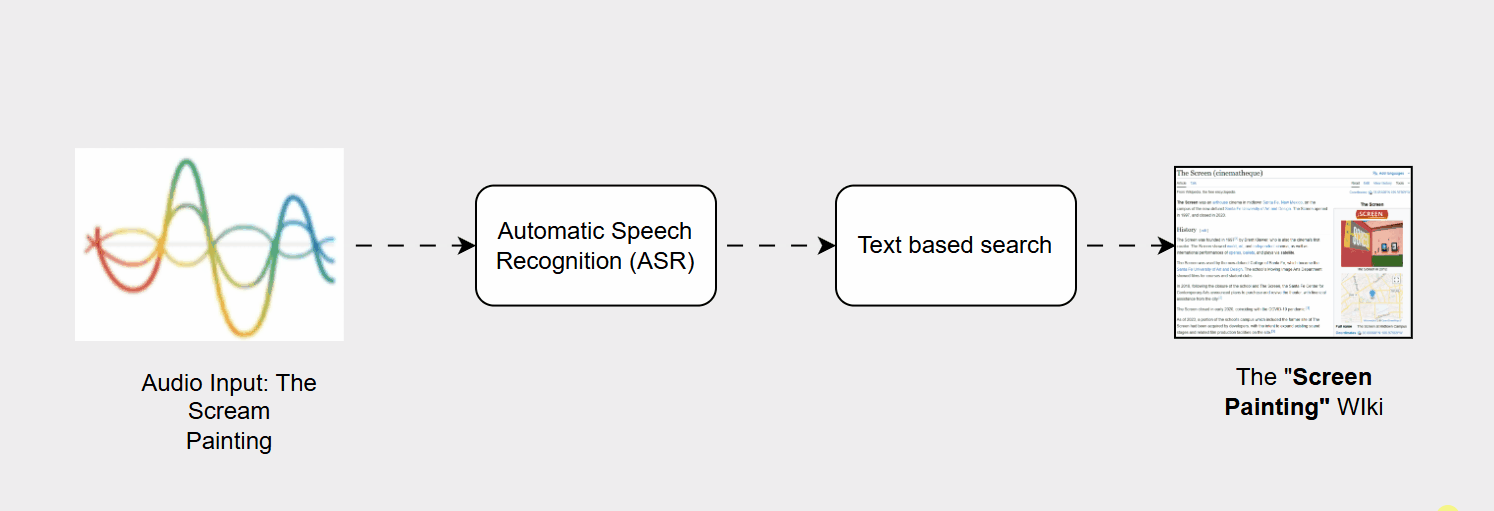
- Automatic Speech Recognition (ASR): This initial component was tasked with converting the user’s acoustic signal (their voice) into a sequence of text characters, or a transcript.
- Information Retrieval (IR): The resulting text transcript was then passed to a separate search engine component, which used standard text-based indexing and ranking methods to locate and deliver the most relevant results.
This modular approach, while pioneering, treated the tasks of speech recognition and search retrieval as separate, sequential problems. This structure defined the performance limits and failure modes of voice search for many years, as a failure in the initial stage inevitably compromised the final output.

Limitations of Cascade Modeling and ASR
The cascade model, despite continuous improvements in ASR systems, suffered from a critical vulnerability known as error propagation. This phenomenon occurs when an error in an early stage of a multi-stage pipeline is passed down to subsequent stages, where it is often amplified and becomes irreversible.
The primary limitations include:
- Transcription Errors (ASR Vulnerability): ASR systems are highly susceptible to variations in acoustic input, such as background noise, differing accents, unusual pronunciation, or the use of out-of-vocabulary (OOV) words (names, slang, or new jargon). A minor transcription error for example, mishearing "The Scream painting" as "The screen painting" could drastically alter the semantic meaning of the query.
- Irreversible Information Loss: Once the audio signal is reduced to a single text string, all the rich, non-lexical information contained in the speech like intonation, emphasis, and acoustic context is lost. This context, which might have helped clarify an ambiguous query, cannot be recovered by the downstream IR system.
- Performance Gap: Evaluation studies often compared a real-world Cascade ASR system (prone to errors) against a Cascade Groundtruth system (simulated perfect ASR using human-verified transcripts). The persistent performance gap between these two demonstrated that even highly advanced search engines could not compensate for ASR failures. Furthermore, the Word Error Rate (WER), the standard metric for ASR accuracy, did not reliably correlate with the final retrieval quality across all languages and queries, underscoring the limitations of relying on text fidelity alone.
How Speech-to-Retrieval Works
S2R overcomes the limitations of the cascade model by replacing the ASR intermediary with a mechanism that directly aligns the user's spoken intent with the relevant search content. This is achieved through a dual-encoder architecture and the concept of semantic embeddings.
- Direct Encoding: The S2R system utilizes a specialized audio encoder neural network. When a user speaks a query, the raw audio is streamed into this encoder, which transforms the sound wave into a dense, numerical vector known as an audio embedding. This embedding is a high-dimensional representation that captures the query’s semantic meaning, regardless of minor acoustic imperfections.
- Parallel Document Encoding: Simultaneously, all searchable content web pages, knowledge graph entities, and previous queries is processed by a separate, but coordinated, document encoder network. This creates a vast index of pre-computed document embeddings, each representing the meaning of a piece of information.
- Joint Semantic Space: The core ingenuity lies in training both encoders to map semantically similar inputs (a spoken query about "Eiffel Tower height" and a text document containing "The height of the Eiffel Tower") to vector representations that are geometrically close in the shared, high-dimensional embedding space.
- Retrieval: When a spoken query's audio embedding is generated, the system performs a rapid search across the index of document embeddings. The retrieval process identifies the documents whose embeddings are closest to the query embedding, effectively bypassing the need for a text transcript.
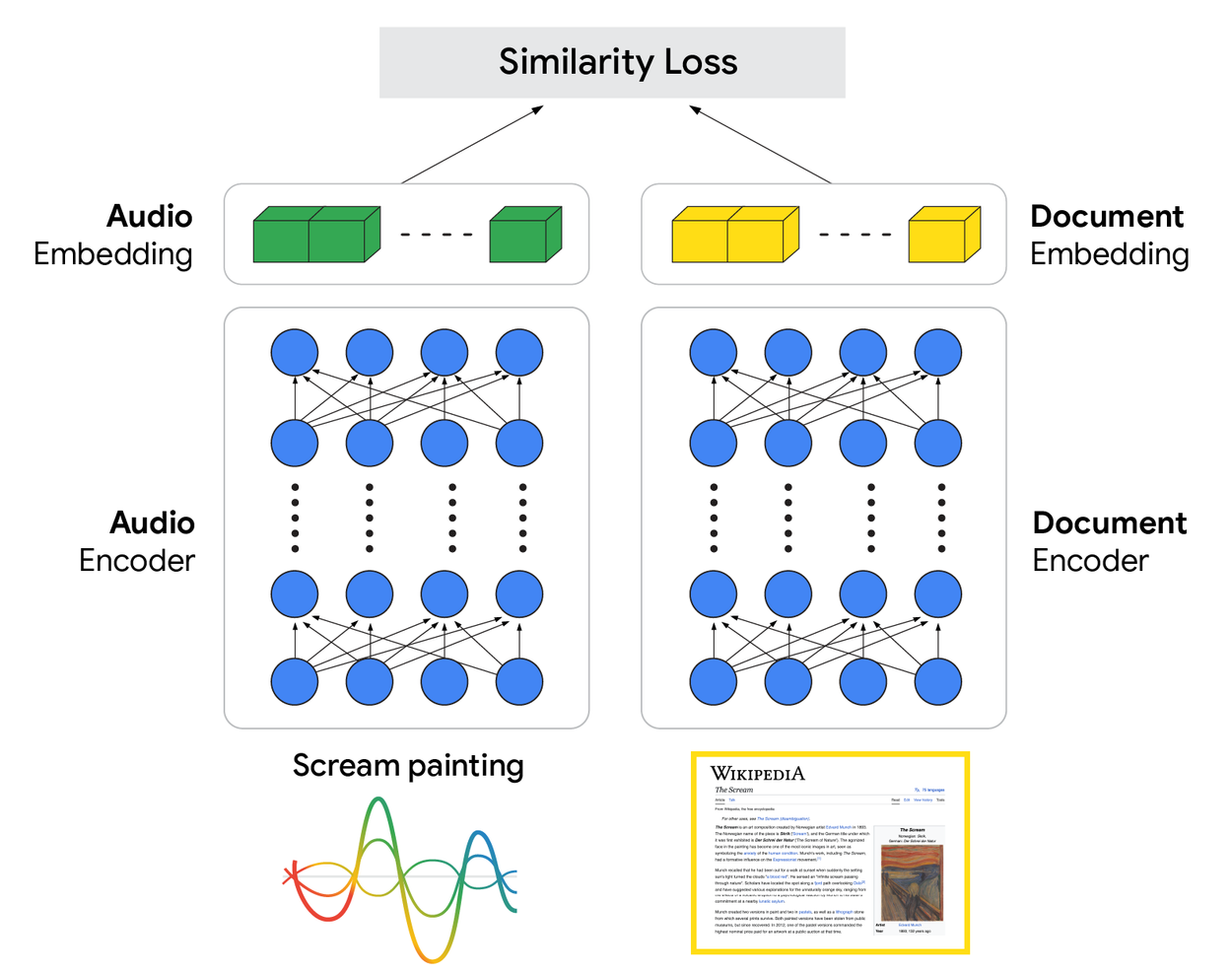
From Speech to Embedding: The New Workflow
The transition from the old "Speech → Text → Retrieval" cascade to the new "Speech → Embedding → Retrieval" workflow represents the architectural change:
- Input: User speaks a query (e.g., "What time is the sunset today?").
- Semantic Encoding: The audio stream is fed directly into the Audio Encoder, which outputs a query vector Qaudio.
- Indexing: The search index contains pre-computed document vectors D1,D2,…,DN, created by the Document Encoder.
- Matching (Retrieval): The system computes a similarity score (often using cosine similarity) between Qaudio and every document vector Di. The documents with the highest similarity scores are retrieved as initial candidates.
- Ranking: These candidates are then passed to the robust, existing Google search ranking system, which uses hundreds of additional signals to determine the final order and present the answer to the user.
This approach ensures that the fundamental search and ranking intelligence remains intact, while the initial, most fragile part of the pipeline the reliance on perfect transcription is replaced with a direct semantic representation derived from the audio itself.
Advantages of S2R Over Traditional Methods
The shift to the S2R architecture delivers several key performance benefits:
Real-world Applications and Use Cases
The impact of S2R extends across the entire ecosystem of Google’s voice-enabled products:
- Voice Search and Assistant: This is the most direct application. Users experience faster and more accurate results when using voice commands on smartphones, tablets, and desktop search interfaces.
- Smart Home Devices: The increased robustness to ambient noise and remote speaking positions significantly improves the reliability of smart speakers and displays, making simple commands (like controlling lights or setting timers) more consistent.
- Accessibility: For users with speech impediments, non-native accents, or highly regional dialects, S2R’s ability to generalize beyond strict lexical matching provides a more inclusive and accessible voice interface.
- Hands-Free Environments: In critical scenarios, such as driving or cooking, where accuracy and speed are paramount, the improved reliability ensures safer and less frustrating hands-free control.
Multilingual Expansion and Performance
The S2R architecture offers profound benefits for multilingual deployment, which is critical for a global service like Google Search.
Traditional ASR often required training massive, separate models for each language, which was particularly challenging for low-resource languages (those with limited available labeled training data).
S2R facilitates multilingual expansion by:
- Shared Semantic Space: The core principle of mapping sound to a universal meaning vector allows for a degree of knowledge transfer across languages. The system can be trained to place similar concepts spoken in different languages (e.g., "cat" in English, "gato" in Spanish) near each other in the shared embedding space.
- Enhanced Code-Switching: In communities where speakers frequently alternate between two or more languages within a single utterance (known as code-switching), S2R's intent-focused retrieval is far more effective than a traditional ASR system that would struggle to handle the mixed lexicon.
- Faster Global Rollout: By focusing on the direct alignment of speech to retrieval targets, Google can more efficiently deploy high-quality voice search to a greater number of languages and regional variants, expanding the global reach of its services.
Technical Insights: Embedding, Ranking, and Privacy
Embedding Space
The "magic" of S2R resides in the dual-encoder architecture. The networks are trained using a contrastive learning objective, which iteratively fine-tunes the encoders to maximize the similarity score between a given spoken query and its relevant search document, while simultaneously minimizing the score for irrelevant documents. This process creates the highly functional semantic embedding space that is key to direct retrieval.
Ranking Integration
Critically, S2R does not replace the entire search stack. The audio embedding is used for the initial retrieval of candidate documents. These candidates are then ranked by the highly sophisticated, mature Google search ranking system, which incorporates hundreds of signals (such as quality, freshness, and user personalization) to determine the definitive order of results. S2R acts as a powerful, more robust query generator for the subsequent ranking stage.
Privacy Considerations
Privacy in voice technology is non-negotiable. Google's S2R system is designed to process the spoken query into an anonymized, numerical embedding. Voice queries are typically processed under strict data governance policies, and it is the numerical embedding vector a highly abstracted representation of intent that is used for the search, not the raw, identifiable audio stream itself. Users are generally provided with granular controls over their voice activity data.
Challenges and Future Directions
Despite its significant advancements, S2R presents ongoing challenges and outlines clear directions for future research:
The ongoing work in S2R focuses on further closing the performance gap with the theoretical "perfect transcription" system and expanding its capability into more complex, natural human communication patterns.
Conclusion and Outlook
Google's Speech-to-Retrieval (S2R) technology represents a decisive evolution in the field of speech processing and information retrieval. By moving away from the fragile, text-dependent cascade model toward a direct sound-to-meaning mapping via semantic embeddings, S2R has delivered substantial, measurable improvements in voice search accuracy, speed, and global accessibility. It establishes a robust, intent-aligned architecture that is better equipped to handle the natural variability of human speech, from differing accents to noisy environments. S2R is not merely an incremental update; it is a fundamental re-engineering that underpins the next generation of intuitive, reliable, and globally inclusive voice-enabled computing.
Inspire Others – Share Now
Agentic AI Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own AI Agents
EV
Saksham
India’s Only 1st Ever Offline Hands-on program that adds 4 Global Certificates while making you a real engineer who has built their own vehicle
Agentic AI LeadCamp
From AI User to AI Agent Builder — Capabl empowers non-coding professionals to ride the AI wave in just 4 days.
Agentic AI MasterCamp
A complete deployment ready program for Developers, Freelancers & Product Managers to be Agentic AI professionals

.png)
Table of Contents
1) Introduction to Speech-to-Retrieval (S2R)
2)Evolution of Voice Search Technology
3) Limitations of Cascade Modeling and ASR
4) How Speech-to-Retrieval Works
5) From Speech to Embedding: The New Workflow
6) Advantages of S2R Over Traditional Methods
7) Real-world Applications and Use Cases
8) Multilingual Expansion and Performance
9) Challenges and Future Directions
10) Conclusion and Outlook



